Comment nous travaillons : AI skills
Fondateur solo + IA + consultants CyFun + conseillers.
TL;DR
Easy Cyber Protection est la plateforme de conformité native CyFun pour les MSP qui livrent l'audit-readiness NIS2 aux PME belges. White-label, local-first, construite pour le canal que les PME font déjà confiance.
Cet article devrait vous donner une idée de la façon dont nous construisons, maintenons et servons cette plateforme. Et nos clients.
La stack d'agents IA tourne sur des procédures opérationnelles standardisées que nous appelons des «skills» : règles écrites, contraintes et exemples qui disent à l'IA comment chaque type de travail se fait.
Actuellement 35 skills (~183 000 mots), plus 70+ documents internes (~88 000 mots) et 80+ fichiers de planification (~103 000 mots) que les agents lisent pour le contexte.
Derrière : un fondateur (20+ ans en IT, une décennie de SaaS en production), des consultants CyFun externes et des conseillers.
Ci-dessous 9 skills d'exemple sur ces 35, avec leur vraie sortie. Théorie après les exemples.
Cartoon — sujet en entrée, cartoon éditorial en sortie
Entrée : une ligne, sujet et ton.
Le skill déduit le reste tout seul : un scénario en trois panneaux, lesquels des deux personnages récurrents (fiches de personnage versionnées pour Fred et Wilma, actuellement v5) apparaissent, la chute, trois appels à l'API d'édition d'image avec différentes graines, et le gagnant que je choisis ensuite.
Sous le capot : ~5 800 mots d'instructions de prompt et de flux de travail, 4 sorties publiques en exemple, plus un skill image séparé que celui-ci appelle pour le rendu effectif.
Ce que vous voyez sous ce bloc n'est pas généré par IA sans relecture. Ça sort de cette chaîne et c'est l'humain (moi) qui l'a approuvé.
Vitrine: fiches de personnage


Les fiches de personnage pour Fred et Wilma (v5). Six vues en rotation plus une pose de face, transmises à l'API d'édition d'image pour que les personnages restent cohérents sur des centaines de cartoons.
Vitrine: règle d'humour (excerpt de SKILL.md)
The humor must be completely self-explanatory: no names,
no context needed, no backstory. A stranger seeing this
for the first time should immediately get it and smile.
Neither character is "right" or "wrong" — they're just two
people who know each other's quirks inside out.
This backstory is for YOUR reference only — it informs
the humor but NEVER appears in captions. Captions must
work for anyone, regardless of whether they know the
characters.Un excerpt de la spec du skill — la règle qui guide l'humour. Pas une recette, juste le cadre :
Vitrine: exemple de sortie
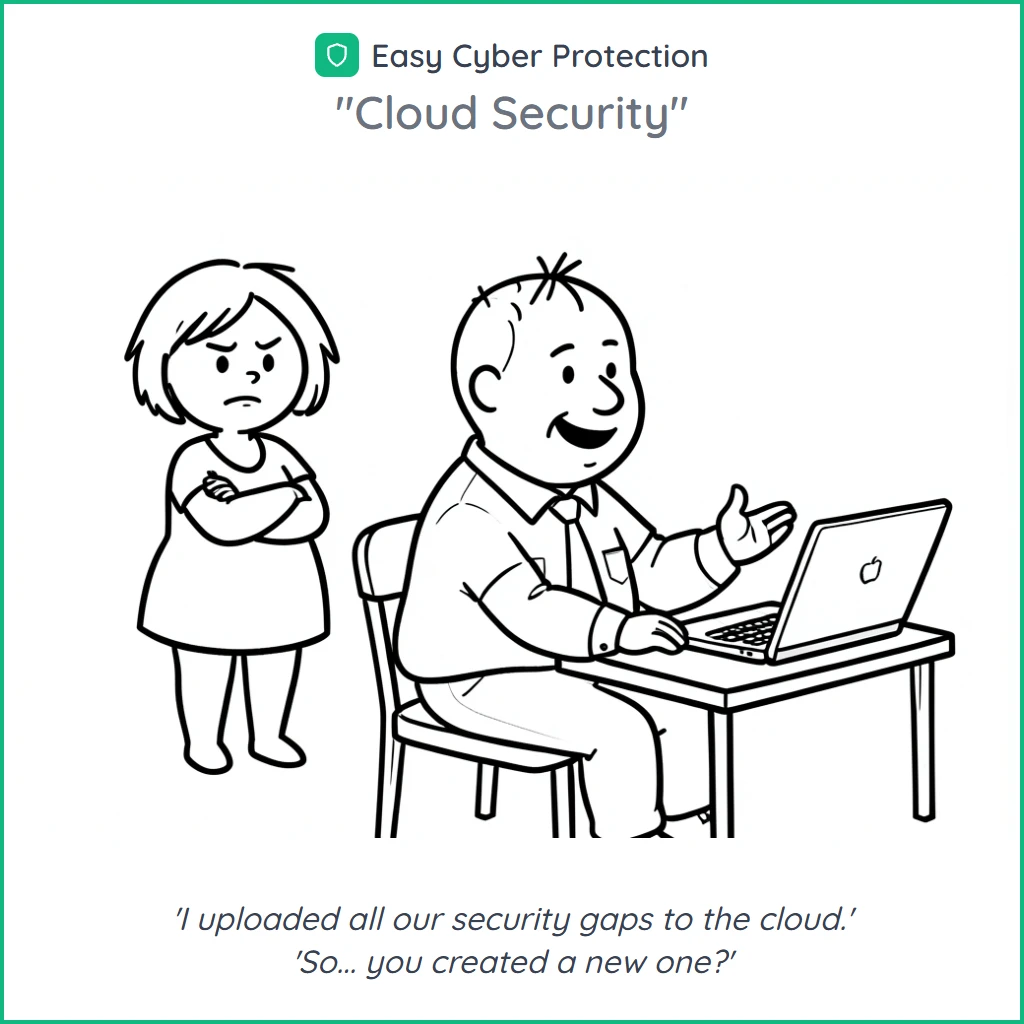


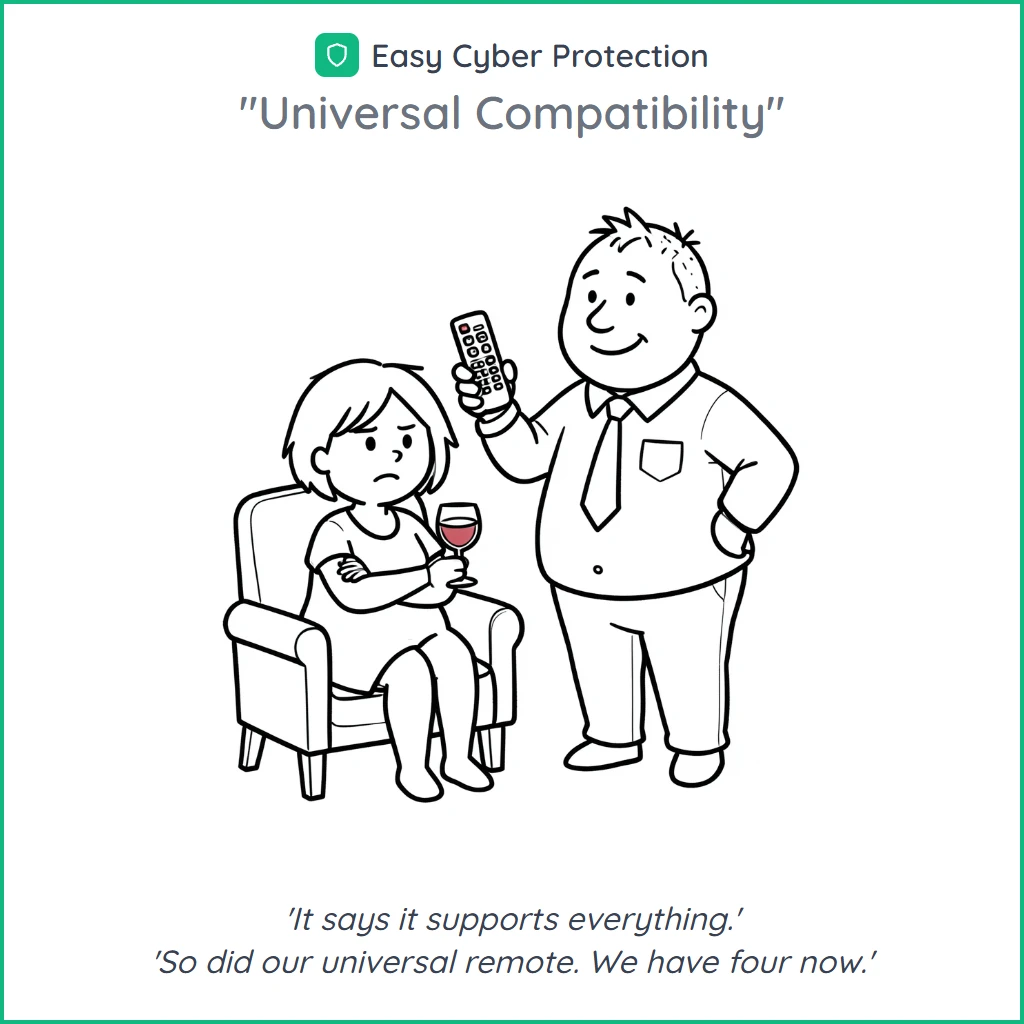
Une poignée de cartoons générés via le skill cartoon. Chacun part d'un sujet ; le skill déduit scénario, personnages, panneaux et caption ; je choisis la version qui marche. Quelques minutes de l'idée à la sortie approuvée.
Strategic advisor — 50+ frameworks, un seul verdict
Le plus gros skill de la stack : presque 100 000 mots d'instructions répartis sur 69 fichiers.
Frameworks de Ray Dalio (vérité radicale), l'algorithme d'élimination en cinq étapes d'Elon Musk, la boucle OODA de John Boyd, les tests «one-way door» de Jeff Bezos, et des dizaines d'autres.
Le skill choisit lui-même les trois à cinq frameworks les plus pertinents pour la décision, les exécute séparément, et synthétise la tension entre leurs verdicts.
Le pivot MSP en février 2026, le rééquilibrage pricing, le choix de stack sans ChatGPT : chacun est passé par cette boucle avant engagement.
Vitrine: décomposition de la bibliothèque de frameworks
| Domain | Frameworks |
|---|---|
| market-gtm | 14 |
| strategic-analysis | 14 |
| thinking-quality | 10 |
| decision-making | 9 |
| execution | 8 |
| systems | 4 |
| financial | 4 |
| creativity | 1 |
| Total | 64 |
64 frameworks nommés sur 8 domaines. Le skill choisit les 3 à 5 plus pertinents pour la question, exécute chacun séparément, et expose la tension entre leurs verdicts. ~100 000 mots d'instructions soutiennent le sélecteur.
Search-visibility (SEO/GEO) — visibilité disciplinée
11 000+ mots sur 8 documents, plus un «tactics ledger» mis à jour chaque semaine qui marque les plays saturés (comme llms.txt, la chasse au nombre de mots, le mass-AI-blog publishing) pour que le skill cesse de les recommander.
L'approche : un modèle d'intent-cluster (pas un funnel) mappé sur le comportement de recherche des acheteurs MSP belges.
Cross-checké contre des sources Google primaires, pas contre des blogs vendor.
Quand Ahrefs a publié une étude contrôlée qui démontait la claim «schema = +3,2x citations», tout le positionnement schema a été rétrogradé à «hygiène, pas driver» en 24 heures.
Vitrine: entrée du tactics-ledger (réelle)
### llms.txt file at site root
- First seen: 2026-05-18
- Mentions: ubiquitous
- Sources: SE Ranking study; Mintlify analysis
- Status: Saturated (ship-and-forget; no measured lift)
- What it claims: Citation lift from LLMs.
- Why it matters for ECP: Already shipped because
it's cheap. Don't claim it as a driver.
- Verdict: Ignore as a lever.Chaque tactique que le discours SEO/GEO plus large pousse est classée ici. Saturé = ne pas mener avec ça. Contredit = enquêter. Le ledger est ce qui empêche le skill de courir derrière ce que Reddit a dit la semaine dernière.
CyFun framework engine — Excel en entrée, dossier d'audit en sortie
Le classeur officiel CyberFundamentals du CCB est un Excel avec des centaines de contrôles répartis sur quatre tiers.
Ce skill le parse, mappe chaque contrôle sur les schémas YAML internes de la plateforme, fusionne les traductions NL/FR/EN, et peut exporter un classeur rempli avec signature Ed25519 qu'un auditeur peut réimporter.
3 500+ mots de logique de parsing plus des scripts pour le round-trip Excel.
C'est pour ça qu'ECP est «CyFun-native» et pas «CyFun supporté» : la source canonique CCB est directement la source de vérité du produit.
Vitrine: nombre de contrôles par tier (depuis l'Excel CCB)
| Tier | Controls |
|---|---|
| Small | 7 |
| Basic | 34 |
| Important | 103 |
| Essential | 268 |
Vitrine: tête du schéma YAML (cyfun-basic/framework.yaml)
id: cyfun-2025-basic
name:
nl: CyFun 2025 Basic
fr: CyFun 2025 Basic
en: CyFun 2025 Basic
description:
en: 34 basic measures for organizations - CCB
CyberFundamentals 2025 BASIC level
(stops 82% of attacks)
maturity_type: levels
satisfaction_threshold: 0.8
uses_entity_types:
[ device, employee, application, supplier,
network, workplace ]Chaque contrôle sur la plateforme est ancré dans ce YAML, qui mappe 1:1 sur l'Excel CCB. Audit-ready signifie que l'Excel de l'auditeur et notre YAML ne peuvent pas diverger.
AI Sentinel — gardien de qualité
Lance chaque jour des fixtures unitaires déterministes plus des scénarios d'intégration en direct contre le pipeline de brouillons IA sur api.easycyberprotection.com.
Détecte la dérive dans la génération, le post-traitement et la couverture des sections manquantes avant qu'elle n'atteigne le lecteur.
Se déclenche plusieurs fois par mois ; parfois c'est le test qui attrape, parfois moi.
C'est ce qui fait taire la voix off «l'IA hallucine», au lieu de simplement le proclamer.
Vitrine: en-tête de scenarios.ts
// AI Sentinel integration scenarios.
// Each scenario hits a real API endpoint with the demo
// account and validates the returned AI content against
// the same rules the pipeline enforces.
import { validateDraftContent, type Violation } from './validators';
export interface ScenarioContext {
baseUrl: string;
token: string;
fetch: typeof fetch;
}Le même validateur que la pipeline de production utilise tourne aussi chaque jour contre les appels API du compte de démo. Il n'y a pas de fossé «le test passe mais la prod est cassée».
Weekly maintenance — l'orchestrateur du jeudi
Un seul skill qui appelle six autres skills en séquence chaque semaine : ccb-guidelines-watch (scanner les nouvelles publications CCB), signals (fusionner GSC + Reddit + Google Trends en un gap-dashboard), weekly-newsletter (composer le CyberWeekly du mercredi), client-microlearning (la leçon hebdomadaire de 2 minutes pour les clients finaux des partenaires MSP), content (mises à jour de linking interne), et une validation finale. C'est ce qui rend une cadence hebdomadaire tenable sans que je passe le samedi sur la planification de contenu.
Vitrine: séquence d'orchestration du jeudi
- 1. ccb-guidelines-watch → scan new CCB publications
- 2. signals → fuse GSC + Reddit + Trends
- 3. weekly-newsletter → compose CyberWeekly draft
- 4. client-microlearning → compose end-client lesson
- 5. content → internal-linking updates
- 6. final validation gate → human approval
Six skills appelés en séquence, avec l'approbation humaine comme dernière étape. Le skill orchestrateur lui-même fait ~1 500 mots de pure séquence.
Improving-skills — la méta-boucle
Le skill qui maintient les skills. 3 400 mots sur quatre docs (consistency, gardening, procedures, SKILL). Détecte quand un skill dérive (la sortie s'écarte de ce que la spec promet), quand un mot-clé déclencheur manque (le skill n'est pas invoqué quand il devrait l'être), et quand de nouveaux patterns émergent de manière répétée dans les conversations et doivent être consolidés formellement comme skill. C'est ce qui maintient une stack IA en vie au-delà du prototype : un skill qui surveille les autres skills.
Vitrine: modèle de learnings (de procedures.md)
### [Category]
#### [Issue Title]
- Context: When does this occur?
- Problem: What goes wrong?
- Solution: How to fix/avoid
- Example: Code snippet if helpful
Keep entries:
- Concise (1-4 bullets)
- Actionable (what to do, not just what happened)
- Discoverable (clear titles for scanning)Quand un problème survient deux fois, il est consigné ici. 400+ lignes de pièges accumulés dans docs/learnings.md à elle seule, plus des règles de cohérence par skill.
Content — l'engine éditorial
6 800 mots sur quatre docs (article-frameworks, components, seo-geo, SKILL). Définit les templates d'articles par intent (explainer de base, pièce de comparaison, guide industrie), les règles de voix praticien, le workflow de factcheck contre des sources primaires, et la règle de parité NL/FR/EN (aucun article ne passe en ligne dans une seule langue). Appelle entre autres le skill search-visibility pour le ciblage de requêtes, et le skill cyfun pour les nombres de contrôles. Documenté à part sur la page «Comment nous écrivons».
Vitrine: quelques règles de voix
- Plain language. No "regulatory instrument"
when "directive" works.
- Primary sources, in-line. No CCB / EU /
named-study link, no number ships.
- Belgian context. CAB auditor reality, not
generic EU theory.
- Practitioner voice. Written by someone who
builds the platform itself.
- No fabricated numbers. No clickbait headlines
that don't match the content underneath.Chaque article #CyberLearn passe par ces règles avant publication. Documenté en détail sur la page Comment nous écrivons .
Skill 9 de l'excerpt
Inattendu : 10 minutes avant Reynolds
(Fictif. Mais Ryan, si tu lis ceci : l'offre tient.)
«J'ai un pitch inattendu avec Ryan Reynolds dans 10 minutes. Crée-moi un pitch deck + contexte.»
Une seule phrase suffit. Le côté ECP — positionnement, couleurs de marque, template de slide, règles de voix, pitches précédents — est déjà dans le contexte de l'agent. Le côté prospect tourne en parallèle : comme Ryan n'est pas dans la CRM, le skill lance un sous-agent pour faire de la recherche en ligne (données publiques sur Mint Mobile, Wrexham AFC, Aviation Gin, Maximum Effort, MNTN) pendant que le skill deck commence déjà à structurer les slides contre le brief. Les deux flux convergent dans le deck + context.html final, largement dans les 9 minutes.
9 minutes plus tard : un deck HTML on-brand de 7 slides et un context.html compagnon pour l'appel. Une minute restante pour le parcourir avant le début de l'appel.

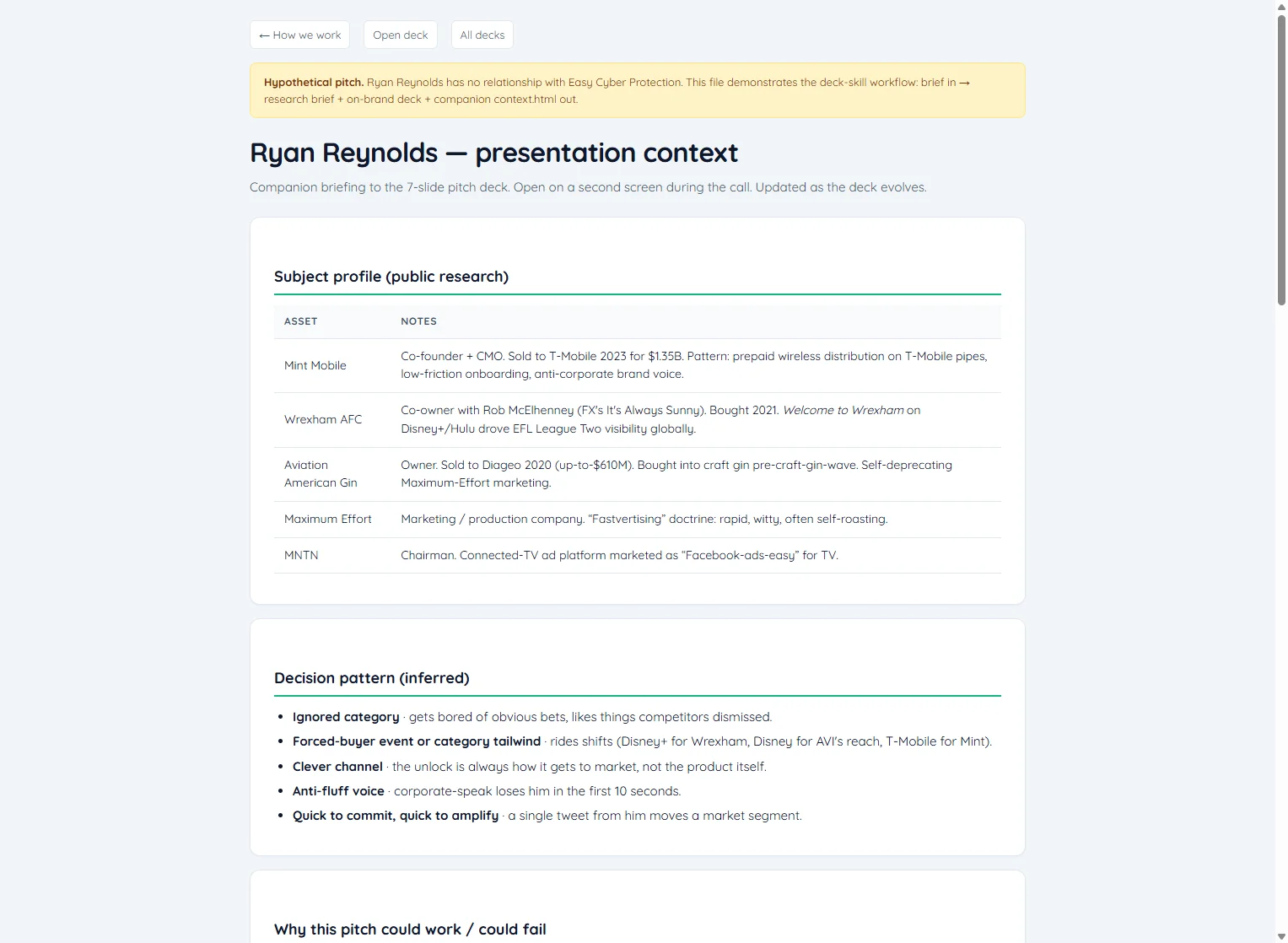
CRM + deck — brief de recherche et pitch en minutes
Deux skills enchaînés.
Le skill CRM tient les prospects en local (pas de SaaS externe) et possède une action meetingPrep qui génère par prospect un briefing : entreprises, leadership, prises de position publiques, critères de décision, forme du deal.
Pour les prospects hors CRM, le skill deck retombe sur une recherche web ciblée.
Le skill deck construit ensuite un deck HTML personnalisé autour de cette contexte, on-brand (police Quicksand, couleurs ECP, prêt pour impression PDF 1280×720), plus un context.html compagnon comme guide de présentation.
Exemple ci-dessus : un pitch fictif de 15 minutes à Ryan Reynolds, produit par le skill deck à partir de recherches publiques sur Mint Mobile, Wrexham AFC, Aviation Gin et MNTN.
Vitrine: preuve de timing (mtimes des fichiers)
$ stat ryan-reynolds-deck/*.html
index.html 12:52:28 (deck written)
context.html 12:54:31 (companion written)
$ stat ryan-reynolds-deck/ | grep Birth
Birth: 2026-05-22 12:45:14 (folder created)
Total : 9m 17s du mkdir aux deux fichiers livrés.Un principe
Les humains posent l'architecture. L'IA remplit les détails à l'intérieur de cette architecture.
C'est tout le principe. L'architecture, c'est ici les contrats typés, les règles éditoriales, les specs d'audit, les modes de défaillance que nous ne tolérons pas. L'IA, c'est des brouillons et propositions qui doivent passer par ces rails avant de partir en ligne.
Vibe-coding versus IA disciplinée
La plupart des SaaS construits avec de l'IA cette année sont vibes-codés : prompt le modèle, livre la sortie, laisse l'utilisateur trouver les bugs.
Ça marche pour des landing pages et des vidéos de démo. Ça ne marche pas pour un logiciel qu'un auditeur va vérifier ligne par ligne contre le classeur CCB.
ECP est construit par l'IA sous des specs qui existent avant que l'IA n'ait le droit d'écrire quoi que ce soit : schémas typés, règles éditoriales, tests d'intégration en forme d'audit, application de citation de sources primaires.
Les rails déterminent ce qui est possible ; l'IA travaille dans ces rails.
Le résultat du vibe-coding, c'est «ça a l'air correct». Le résultat de l'IA disciplinée, c'est «ça survit à la checklist de l'auditeur».
Comment les skills se composent dans le temps
Chaque skill de la stack a commencé brut. Le tout premier cartoon a pris une journée entière : rédiger la chute, esquisser les personnages, lutter avec l'API d'image, choisir parmi de nombreux rendus ratés. Aujourd'hui c'est : un sujet en entrée, trois options en sortie, je choisis le meilleur en quelques secondes.
Ce n'est pas l'IA qui devient plus intelligente. C'est le skill — les prompts, les contraintes, les notes sur les modes de défaillance, les fiches de personnage — qui devient plus dense à chaque usage. Ce qui a marché devient une règle. Ce qui a cassé devient un garde-fou. Ce qui revient trois fois dans une conversation devient un nouveau skill.
Cent usages plus tard, un skill fait en cinq minutes ce qui prenait une journée au début. C'est ça, la composition. C'est aussi pourquoi la stack semble nettement plus rapide chaque mois, sans que les modèles en dessous aient changé.
Preuves
Output concret, ancré dans 20+ ans de pratique et une décennie de SaaS en production. Ce que ça produit :
- 80+ articles #CyberLearn, chacun en trois langues
- Numéros #CyberWeekly hebdomadaires, chaque mercredi depuis décembre 2025
- 100+ migrations de base de données et en augmentation, toutes sous des contrats de schéma typés
- 600+ chaînes de traduction maintenant la parité NL/FR/EN
- Des dizaines de commits par jour en moyenne, tous passant par des contrats typés et des tests d'intégration avant le merge
- 35+ skills spécialisés sous la stack architecturée par l'humain, 9 d'entre eux sont présentés ci-dessous
- 70+ documents internes (architecture, runbooks, learnings) et 15+ Architecture Decision Records
- 80+ artefacts de planification dans la file d'attente work-in-progress, utilisés pour la continuité cross-session avec l'IA
Comment la confiance se gagne
La confiance ne se gagne pas en affirmant que l'IA est sûre. Elle se gagne par ce qui se trouve entre la sortie IA et le client. Nous n'énumérons pas les détails (c'est de la surface concurrentielle), mais voici la forme :
- Chaque chemin de code passe par des contrats typés et des tests d'intégration avant de pouvoir merger.
- Chaque affirmation de contenu passe par une vérification de source primaire avant publication.
- Chaque sortie destinée au client passe par une porte d'approbation humaine.
- Chaque écriture pertinente pour audit passe par event sourcing avec historique signé numériquement.
Les audits, les specs et la porte sont les constantes. L'IA est la variable.
Ce que l'IA nous a apporté, et ce qu'elle n'a pas
Comptabilité honnête.
Apporté :
- +Parité de traduction en NL, FR et EN. Sans IA : anglais uniquement, pour une durée indéterminée.
- +Réponse dans la même semaine aux mises à jour réglementaires. Sans IA : mensuel au mieux.
- +Une bibliothèque de 80+ articles maintenue par une seule personne. Sans IA : peut-être 15.
- +Cartoons éditoriaux en minutes de l'idée à la publication. Sans IA : sous-traiter et perdre la voix.
- +Agents spécialisés (sentinel, coach commercial, strategic advisor) tournant en arrière-plan sans devoir acheter leur propre abonnement SaaS. Sans IA : les sauter ou embaucher.
Non apporté :
- −La nécessité de comprendre la conformité. L'IA ne lit pas l'Excel CCB pour moi ; elle me demande de le lire.
- −L'élimination des tests en forme d'audit. Tout ce qui touche aux données client passe toujours par la signature Ed25519 et l'event sourcing.
- −Un repas gratuit sur les hallucinations. Le Sentinel se déclenche plusieurs fois par mois ; parfois je l'attrape, parfois c'est le test.
- −L'empathie client. Le plancher de cinq appels MSP par semaine reste à moi à parcourir.
Pourquoi l'IA seule n'atteint pas la conformité complète
L'IA peut mapper les contrôles, générer des templates d'évidence, structurer des dossiers d'audit et suivre les mises à jour réglementaires.
L'IA ne peut pas s'asseoir avec le dirigeant et décider de ce qui est vraiment dans le périmètre de son entreprise.
Ne peut pas vérifier physiquement que les règles firewall correspondent réellement à la politique sur papier.
Ne peut pas faire l'arbitrage quand un contrôle entre en conflit avec la réalité opérationnelle d'une PME.
L'audit-readiness est un processus assisté par IA avec des humains dans la boucle, pas un produit AI-only. Quiconque vend «conformité via IA» sans l'étape humaine vend une démo, pas un produit.
Ce n'est pas de la philosophie ; c'est ainsi que nous utilisons ECP en interne.
Lire l'article complet : Pourquoi l'IA seule n'atteint pas la conformité →Ce n'est pas une première expérience avec l'IA
20+ ans en IT et innovation management, notamment chez Eurocontrol (l'organisation derrière le trafic aérien européen) et auprès de PME belges, ont façonné ma définition de «en production» : testé, validé, observable, récupérable.
ECP tourne sur cette même barre. L'IA accélère le travail ; l'IA ne fait pas baisser la barre.
Et pour ceux qui se demandent si tout cela va durer : Core bv fait tourner du SaaS en production depuis plus d'une décennie. ECP n'est pas une expérience qui repartira hors ligne dans douze mois.
Sceptique ? Bien.
C'est sain. Tout ce qui est construit avec de l'IA mérite la suspicion jusqu'à preuve du contraire. Votre vrai test n'est pas de lire cette page ; c'est d'utiliser le produit. Trouvez un bug et dites-le moi. Les vrais problèmes sont corrigés rapidement.
Essayer le produitP.S. — oui, cet article a aussi été drafté par IA avec un humain dans la boucle. Dogfood du haut en bas.