TL;DR
Easy Cyber Protection is the CyFun-native compliance platform for MSPs delivering NIS2 audit-readiness to Belgian SMEs. White-label, local-first, built for the channel SMEs already trust.
This article should give you an idea of how we build, maintain and service that platform. And our customers.
The AI agent stack runs on standard operating procedures we call "skills": written rules, constraints and examples that tell the AI how each kind of work gets done.
Currently 35 skills (~183,000 words), plus 70+ internal docs (~88,000 words) and 80+ planning files (~103,000 words) the agents read for context.
Behind it: one founder (20+ years IT, a decade of production SaaS), external CyFun consultants, and advisors.
Below: 9 sample skills out of those 35, with their real output. Theory after the examples.
Cartoon — subject in, editorial cartoon out
Input is one line: a subject and a tone.
The skill derives the rest: a three-panel scenario, which of the two recurring characters (versioned character sheets for Fred and Wilma, currently v5) appear, the punchline, three image-edit API calls with different seeds, and the winner for my human pick.
Under the hood: ~5,800 words of prompt and workflow instructions, four publicly visible example outputs, and a separate image skill that this skill calls for the actual rendering.
What you see below this block is not AI-generated without review. It came out of this pipeline and was approved by the human (me).
Exhibit: character sheets


The character sheets for Fred and Wilma (v5). Six rotation views plus a front-facing pose, fed to the image-edit API so the characters stay consistent across hundreds of cartoons.
Exhibit: humour rule (excerpt from SKILL.md)
The humor must be completely self-explanatory: no names,
no context needed, no backstory. A stranger seeing this
for the first time should immediately get it and smile.
Neither character is "right" or "wrong" — they're just two
people who know each other's quirks inside out.
This backstory is for YOUR reference only — it informs
the humor but NEVER appears in captions. Captions must
work for anyone, regardless of whether they know the
characters.An excerpt from the skill spec — the rule that drives the humour. Not a recipe, just the frame:
Exhibit: sample output
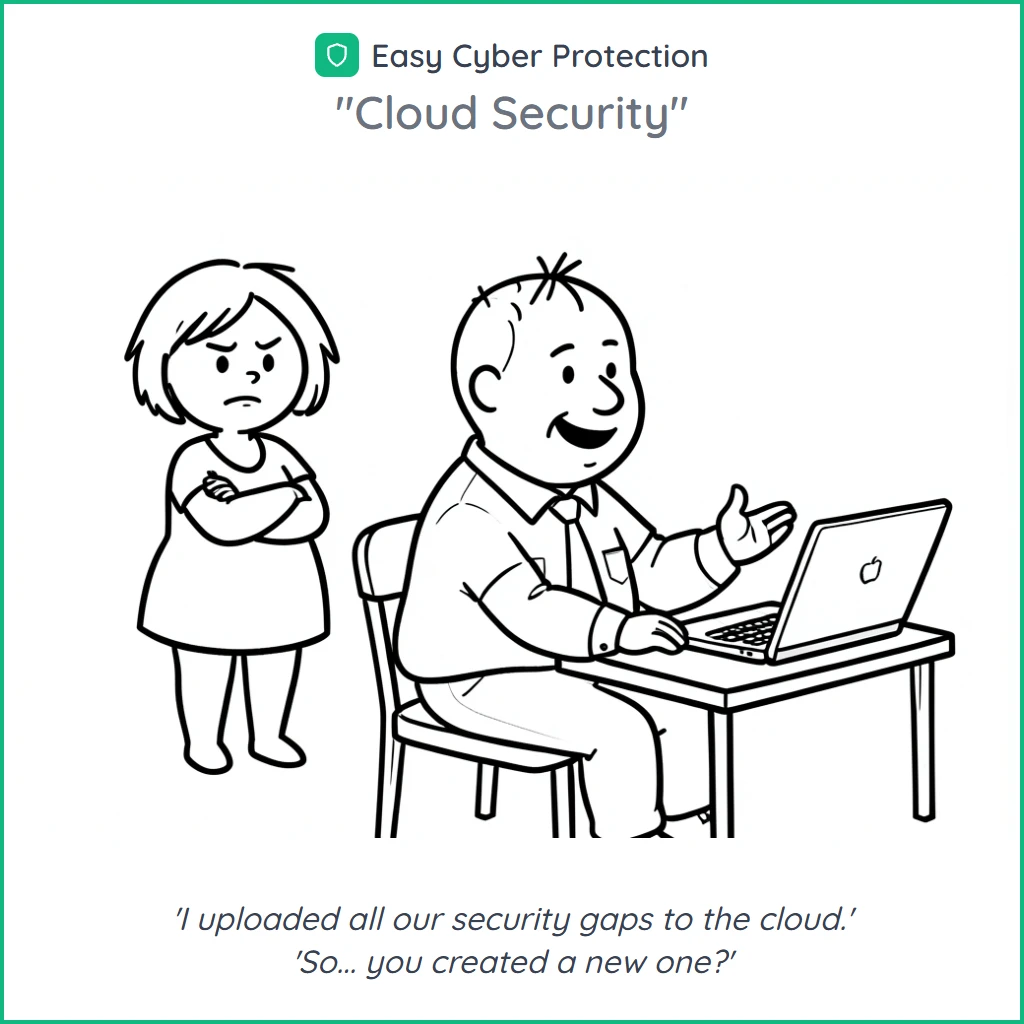


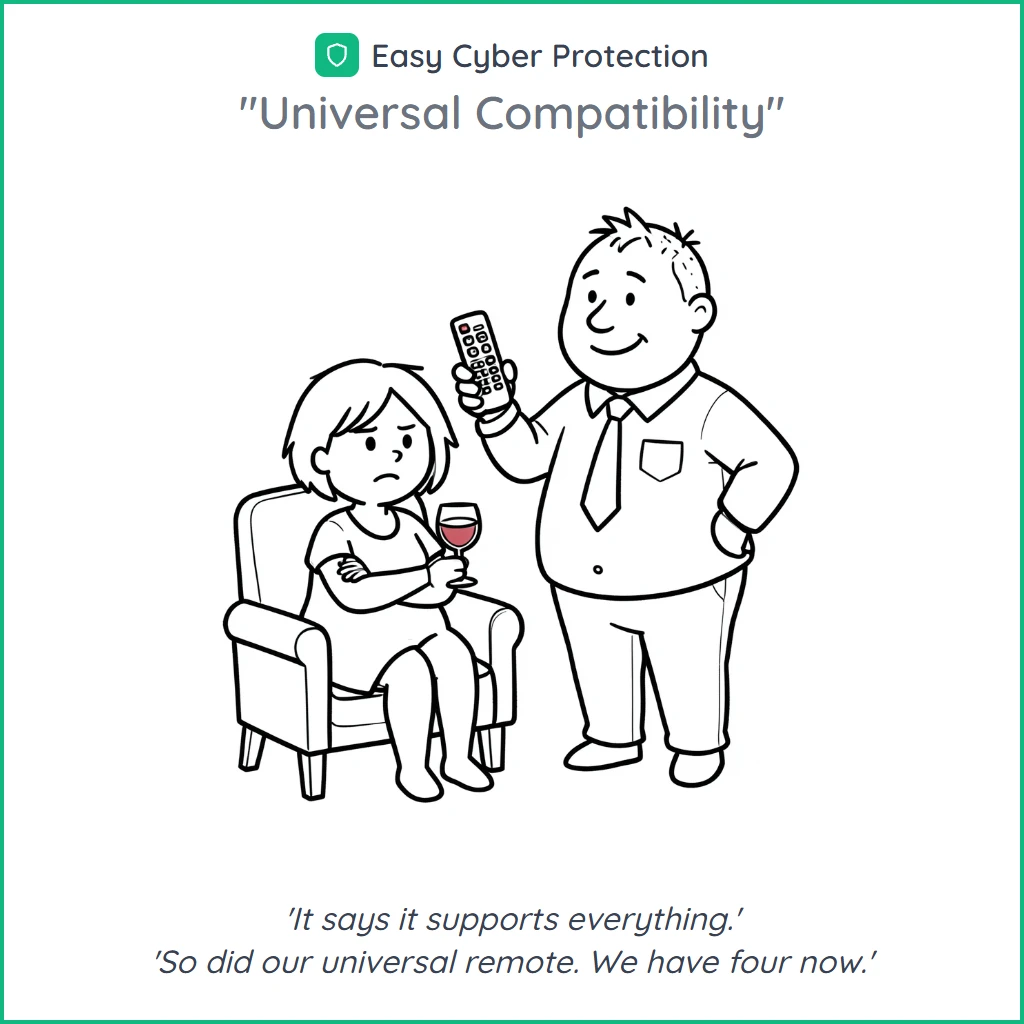
A handful of cartoons generated through the cartoon skill. Each starts from a subject; the skill derives scenario, characters, panels and caption; I pick the version that lands. Minutes from idea to approved output.
Strategic advisor — 50+ frameworks, one verdict
The biggest skill in the stack: nearly 100,000 words of instruction spread across 69 files.
Frameworks from Ray Dalio (radical truth), Elon Musk's five-step elimination algorithm, John Boyd's OODA loop, Jeff Bezos' one-way-door tests, and dozens more.
The skill picks the three-to-five frameworks most relevant to the decision, runs each independently, and synthesises the tension between their verdicts.
The February 2026 MSP pivot, the pricing rebalance, the no-ChatGPT stack choice: each ran through this loop before commitment.
Exhibit: framework library breakdown
| Domain | Frameworks |
|---|---|
| market-gtm | 14 |
| strategic-analysis | 14 |
| thinking-quality | 10 |
| decision-making | 9 |
| execution | 8 |
| systems | 4 |
| financial | 4 |
| creativity | 1 |
| Total | 64 |
64 named frameworks across 8 domains. The skill picks 3-5 most relevant to the question, runs each independently, and surfaces the tension between verdicts. ~100,000 words of instruction back the picker.
Search-visibility (SEO/GEO) — disciplined visibility
11,000+ words across 8 documents, plus a weekly-updated tactics ledger that flags saturated plays (llms.txt, word-count chasing, mass AI-blog publishing) so the skill stops recommending them.
The approach: an intent-cluster model (not a funnel) mapped onto how Belgian MSP buyers actually search.
Cross-checked against primary Google sources, not vendor blog posts.
When Ahrefs published a controlled study breaking the "schema = +3.2x citations" claim, the entire schema positioning was demoted to "hygiene, not driver" within 24 hours.
Exhibit: tactics-ledger entry (real)
### llms.txt file at site root
- First seen: 2026-05-18
- Mentions: ubiquitous
- Sources: SE Ranking study; Mintlify analysis
- Status: Saturated (ship-and-forget; no measured lift)
- What it claims: Citation lift from LLMs.
- Why it matters for ECP: Already shipped because
it's cheap. Don't claim it as a driver.
- Verdict: Ignore as a lever.Every tactic the broader SEO/GEO discourse pushes gets classified here. Saturated = don't lead with it. Contradicted = investigate. The ledger is what stops the skill from chasing whatever Reddit said last week.
CyFun framework engine — Excel in, audit pack out
The CCB's official CyberFundamentals workbook is an Excel with hundreds of controls split across four tiers.
This skill parses it, maps each control onto the platform's internal YAML schemas, merges NL/FR/EN translations, and can export a filled workbook with Ed25519 signature that an auditor can re-import.
3,500+ words of parser logic plus scripts for the Excel round-trip.
It's why ECP is "CyFun-native" and not "CyFun supported": the canonical CCB source is the product's source of truth.
Exhibit: tier control counts (parsed from CCB Excel)
| Tier | Controls |
|---|---|
| Small | 7 |
| Basic | 34 |
| Important | 103 |
| Essential | 268 |
Exhibit: YAML schema head (cyfun-basic/framework.yaml)
id: cyfun-2025-basic
name:
nl: CyFun 2025 Basic
fr: CyFun 2025 Basic
en: CyFun 2025 Basic
description:
en: 34 basic measures for organizations - CCB
CyberFundamentals 2025 BASIC level
(stops 82% of attacks)
maturity_type: levels
satisfaction_threshold: 0.8
uses_entity_types:
[ device, employee, application, supplier,
network, workplace ]Every control on the platform is grounded in this YAML, which maps 1:1 to the CCB Excel. Audit-ready means the auditor's Excel and our YAML cannot disagree.
AI Sentinel — quality guard
Runs deterministic unit fixtures plus live integration scenarios against the AI draft pipeline on api.easycyberprotection.com every day.
Catches drift in generation, post-processing and missing-section coverage before it ever reaches a reader.
Fires several times a month; sometimes the test catches it, sometimes I do.
It's what actually silences the "AI hallucinates" voiceover, instead of just claiming it.
Exhibit: scenarios.ts header
// AI Sentinel integration scenarios.
// Each scenario hits a real API endpoint with the demo
// account and validates the returned AI content against
// the same rules the pipeline enforces.
import { validateDraftContent, type Violation } from './validators';
export interface ScenarioContext {
baseUrl: string;
token: string;
fetch: typeof fetch;
}The same validator the production pipeline uses also runs against demo-account API calls daily. There's no "test passes but prod is broken" gap.
Weekly maintenance — the Thursday orchestrator
One skill that calls six others in sequence each week: ccb-guidelines-watch (scan new CCB publications), signals (fuse GSC + Reddit + Google Trends into a gap dashboard), weekly-newsletter (compose Wednesday's CyberWeekly), client-microlearning (the 2-minute weekly lesson for MSP-partner end clients), content (internal-linking updates), and a final validation. It's what makes a weekly cadence sustainable without me sitting in front of content planning on a Saturday.
Exhibit: Thursday orchestration sequence
- 1. ccb-guidelines-watch → scan new CCB publications
- 2. signals → fuse GSC + Reddit + Trends
- 3. weekly-newsletter → compose CyberWeekly draft
- 4. client-microlearning → compose end-client lesson
- 5. content → internal-linking updates
- 6. final validation gate → human approval
Six skills called in order, with human approval as the last step. The orchestrator skill itself is ~1,500 words of pure sequencing.
Improving-skills — the meta-loop
The skill that maintains the skills. 3,400 words across four docs (consistency, gardening, procedures, SKILL). Catches when a skill drifts (output diverges from what its spec promises), when a trigger keyword is missing (the skill isn't getting invoked when it should be), and when new patterns recur enough in conversations to be formally consolidated as a skill. It's what keeps an AI stack alive past the prototype stage: a skill that watches the other skills.
Exhibit: learnings template (from procedures.md)
### [Category]
#### [Issue Title]
- Context: When does this occur?
- Problem: What goes wrong?
- Solution: How to fix/avoid
- Example: Code snippet if helpful
Keep entries:
- Concise (1-4 bullets)
- Actionable (what to do, not just what happened)
- Discoverable (clear titles for scanning)When a problem hits twice, it gets captured here. 400+ lines of accumulated gotchas in docs/learnings.md alone, plus per-skill consistency rules.
Content — the editorial engine
6,800 words across four docs (article-frameworks, components, seo-geo, SKILL). Defines article templates per intent (basic explainer, comparison piece, industry guide), the practitioner-voice rules, the fact-check workflow against primary sources, and the NL/FR/EN parity rule (no article ships in one language alone). Calls the search-visibility skill for query targeting and the cyfun skill for control counts, among others. Documented separately on the "How we write" page.
Exhibit: a few of the voice rules
- Plain language. No "regulatory instrument"
when "directive" works.
- Primary sources, in-line. No CCB / EU /
named-study link, no number ships.
- Belgian context. CAB auditor reality, not
generic EU theory.
- Practitioner voice. Written by someone who
builds the platform itself.
- No fabricated numbers. No clickbait headlines
that don't match the content underneath.Every #CyberLearn article passes these rules before publish. Documented in detail on the How we write page.
Skill 9 of the excerpt
Unexpected: 10 minutes to Reynolds
(Fictitious. But Ryan, if you're reading: the offer stands.)
"I have an unexpected pitch with Ryan Reynolds in 10 minutes. Create me a pitch deck + context."
One sentence is enough. The ECP side — positioning, brand colours, slide template, voice rules, past pitches — is already in the agent's context. The prospect side runs in parallel: since Ryan isn't in the CRM, the skill fires off a sub-agent to do online research (public data on Mint Mobile, Wrexham AFC, Aviation Gin, Maximum Effort, MNTN) while the deck skill starts structuring slides against the brief. Both streams converge into the final deck + context.html, well under the 9-minute mark.
9 minutes later: a 7-slide on-brand HTML deck and a companion context.html for the call. One minute left to skim before the call starts.

CRM + deck — research brief and pitch in minutes
Two skills chained.
The CRM skill holds prospects locally (no external SaaS) and exposes a meetingPrep action that produces a per-prospect briefing: companies, leadership, public positions, decision criteria, deal shape.
For prospects not in the CRM, the deck skill falls back to targeted web research.
The deck skill then builds a personalised on-brand HTML deck (Quicksand font, ECP colours, 1280×720 print-PDF-ready) plus a companion context.html as a presentation guide.
Example above: a fictional 15-minute pitch to Ryan Reynolds, produced by the deck skill from public research on Mint Mobile, Wrexham AFC, Aviation Gin and MNTN.
Exhibit: timing receipt (file mtimes)
$ stat ryan-reynolds-deck/*.html
index.html 12:52:28 (deck written)
context.html 12:54:31 (companion written)
$ stat ryan-reynolds-deck/ | grep Birth
Birth: 2026-05-22 12:45:14 (folder created)
Total: 9m 17s from mkdir to both files shipped.One principle
Humans set the architecture. AI fills the details inside that architecture.
That is the whole principle. Architecture here means the typed contracts, the editorial rules, the audit specs, the failure modes we won't tolerate. AI means drafts and proposals that have to pass those rails before they ship.
Vibes-coding versus disciplined AI
Most AI-built SaaS this year is vibes-coded: prompt the model, ship the output, let the user find the bugs.
That works for landing pages and demo videos. It does not work for software an auditor will check line by line against the CCB workbook.
ECP is built by AI under specs that exist before the AI is allowed to write anything: typed schemas, editorial rules, audit-shape integration tests, primary-source citation enforcement.
The rails determine what's possible; AI works inside them.
The output of vibes-coding is "looks right". The output of disciplined AI is "survives the auditor's checklist".
How skills compound
Every skill in the stack started rough. The first-ever cartoon took a full day: drafting the punchline, sketching the characters, fighting the image API, picking from many failed renders. Today it is: one subject in, three options out, I pick the best in seconds.
That is not the AI getting smarter. It is the skill — the prompts, the constraints, the failure-mode notes, the character sheets — getting denser with every use. What worked becomes a rule. What broke becomes a guardrail. What recurs three times in a conversation becomes a new skill.
A hundred uses in, a skill does in five minutes what took a full day the first time. That is the compounding. It is also why the stack feels noticeably faster month over month, without the underlying models changing.
Receipts
Concrete output, anchored in 20+ years of practice and a decade of production SaaS. What this produces:
- 80+ #CyberLearn articles, each in three languages
- Weekly #CyberWeekly issues, every Wednesday since December 2025
- 100+ database migrations and counting, all under typed schema contracts
- 600+ translation strings holding NL/FR/EN parity
- Tens of commits per day on average, all passing typed contracts and integration tests before merge
- 35+ specialist skills under the human-architected stack; 9 of them are toured below
- 70+ internal docs (architecture, runbooks, learnings) and 15+ Architecture Decision Records
- 80+ planning artifacts in the work-in-progress queue, used for cross-session continuity with the AI
How trust gets earned
Trust isn't earned by claiming AI is safe. It's earned by what sits between the AI output and the customer. We won't enumerate the specifics (that's competitive surface), but the shape:
- Every code path passes typed contracts and integration tests before it can merge.
- Every content claim runs through a primary-source check before publish.
- Every customer-facing output crosses a human approval gate.
- Every audit-relevant write goes through event sourcing with a signed history.
The audits, the specs and the gate are the constants. AI is the variable.
What AI bought us, and what it didn't
Honest accounting.
Bought:
- +Translation parity across NL, FR and EN. Without AI: English-only, indefinitely.
- +Same-week response to regulatory updates. Without AI: monthly at best.
- +A library of 80+ articles maintained by one person. Without AI: maybe 15.
- +Editorial cartoons in minutes from idea to publish. Without AI: outsource, lose the voice.
- +Specialist agents (sentinel, sales coach, strategic advisor) running on the side without buying their own SaaS subscription. Without AI: skip them or hire.
Didn't buy:
- −The need to understand compliance. AI doesn't read the CCB Excel for me; it asks me to read it.
- −Removing audit-shape testing. Anything that touches client data still goes through Ed25519 signing and event sourcing.
- −A free lunch on hallucinations. The Sentinel fires several times a month; sometimes I catch it, sometimes the test does.
- −Customer empathy. The five-MSP-calls-per-week floor is still mine to walk.
Why AI alone doesn't reach full compliance
AI can map controls, generate evidence templates, structure audit packs, and track regulatory updates.
AI cannot sit with the SME owner and decide what's actually in scope for their business.
Cannot physically verify the firewall rules really match the policy on paper.
Cannot make the judgment call when a control conflicts with the operational reality of an SME.
Audit-readiness is an AI-assisted process with humans in the loop, not an AI-only product. Anyone selling "compliance via AI" without the human step is selling a demo, not a product.
This isn't philosophy. It's how we use ECP internally.
Read the full piece: Why AI alone can't reach compliance →This isn't a first-time-with-AI experiment
20+ years across IT and innovation management, including Eurocontrol (the organisation behind European air traffic) and Belgian SMEs, shaped my definition of "in production": tested, validated, observable, recoverable.
ECP runs on that same bar. AI speeds the work; AI does not lower the bar.
And for those wondering whether this is here to stay: Core bv has been running production SaaS for more than a decade. ECP isn't an experiment that disappears in twelve months.
Skeptical? Good.
You should be. Anything built with AI deserves skepticism until it's proven. Your real test isn't reading this page; it's using the product. Find a bug and tell me. Real issues get fixed quickly.
Try the productP.S. — yes, this article was also drafted by AI with a human in the loop. Dogfood all the way down.